
Las distribuciones de GNU/Linux incluyen una gran cantidad de programas para manejar texto, la mayoría de los cuales son proporcionados por las utilidades principales de GNU. Hay algo de una curva de aprendizaje, pero estas utilidades pueden resultar muy útiles y eficientes cuando se usan correctamente.
Aquí hay trece poderosas herramientas de manipulación de texto que todo usuario de línea de comandos debería conocer.
1. gato
Cat fue diseñado para estafargatocrear archivos, pero se usa con mayor frecuencia para mostrar un solo archivo. Sin ningún argumento, cat lee la entrada estándar hasta que se presiona Ctrl + D (desde la terminal o desde otra salida del programa si se usa una tubería). La entrada estándar también se puede especificar explícitamente con un -.
Cat tiene una serie de opciones útiles, en particular:
-Aimprime “$” al final de cada línea y muestra los caracteres que no se imprimen utilizando la notación de intercalación.-nnúmeros todas las líneas.-blíneas de números que no están en blanco.-sreduce una serie de líneas en blanco a una sola línea en blanco.
En el siguiente ejemplo, estamos concatenando y numerando el contenido del archivo1, la entrada estándar y el archivo3.
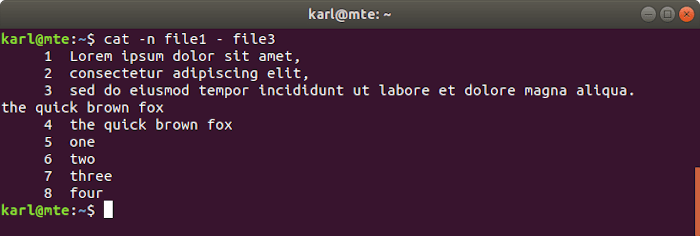
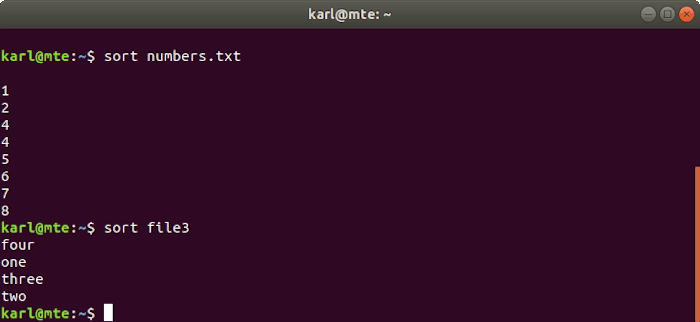
2. ordenar
Como su nombre indica, sort ordena el contenido de los archivos alfabética y numéricamente.
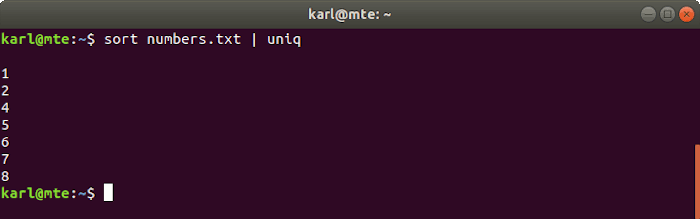
3. único
Uniq toma un archivo ordenado y elimina las líneas duplicadas. A menudo está encadenado con sort en un solo comando.
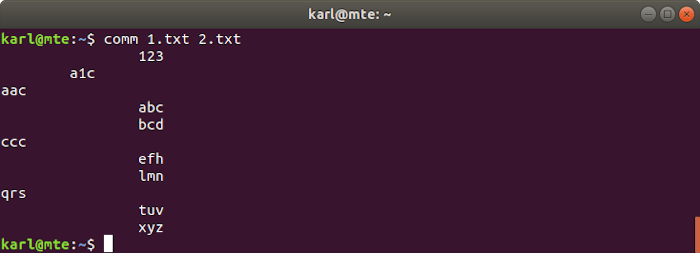
4. comunicación
Comm se utiliza para comparar dos archivos ordenados, línea por línea. Produce tres columnas: las dos primeras columnas contienen líneas únicas para el primer y segundo archivo respectivamente, y la tercera muestra las que se encuentran en ambos archivos.
5. cortar
Cortar se utiliza para recuperar secciones específicas de líneas, en función de caracteres, campos o bytes. Puede leer desde un archivo o desde una entrada estándar si no se especifica ningún archivo.
Corte por posición del personaje
los -c La opción especifica una posición de un solo carácter o uno o más rangos de caracteres.
Por ejemplo:
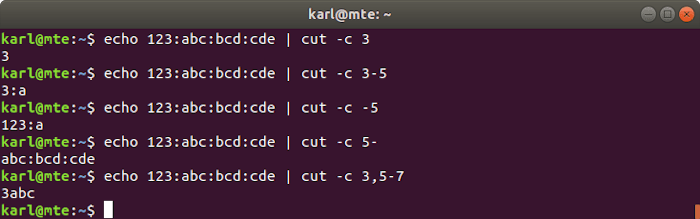
-c 3: el tercer carácter.-c 3-5: del 3° al 5° carácter.-c -5o-c 1-5: del 1° al 5° carácter.-c 5-: desde el 5º carácter hasta el final de la línea.-c 3,5-7: el 3º y del 5º al 7º carácter.
Corte por campo
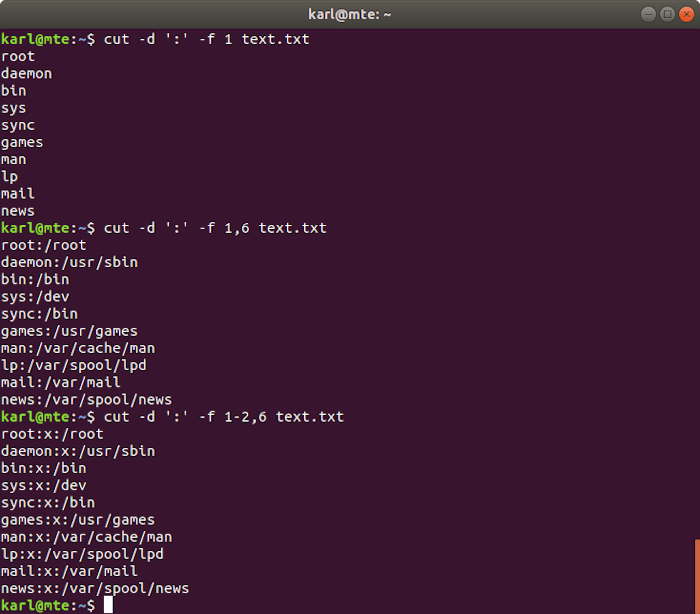
Los campos están separados por un delimitador que consta de un solo carácter, que se especifica con el -d opción. los -f La opción selecciona una posición de campo o uno o más rangos de campos utilizando el mismo formato que el anterior.
6. dos2unix
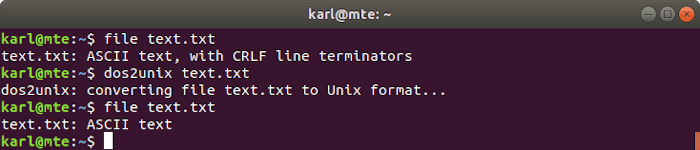
GNU/Linux y Unix normalmente terminan las líneas de texto con un salto de línea (LF), mientras que Windows usa retorno de carro y salto de línea (CRLF). Pueden surgir problemas de compatibilidad cuando se maneja texto CRLF en Linux, que es donde entra dos2unix. Convierte terminadores CRLF a LF.
En el siguiente ejemplo, el file El comando se usa para verificar el formato de texto antes y después de usar dos2unix.
7. doblar
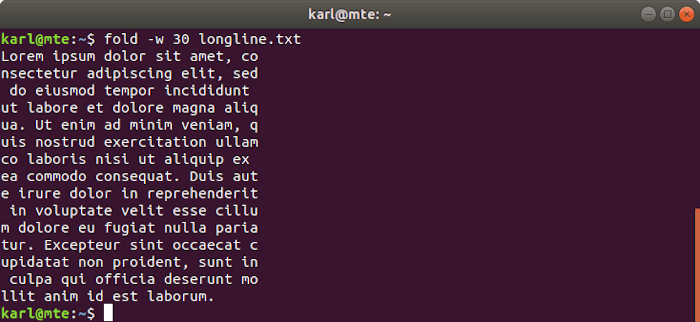
Para que las líneas largas de texto sean más fáciles de leer y manejar, puede usar foldque ajusta las líneas a un ancho especificado.
Fold coincide estrictamente con el ancho especificado de forma predeterminada, separando palabras cuando sea necesario.
Si no desea dividir las palabras, puede utilizar el -s Opción de romper en los espacios.
fold -w 30 -s longline.txt
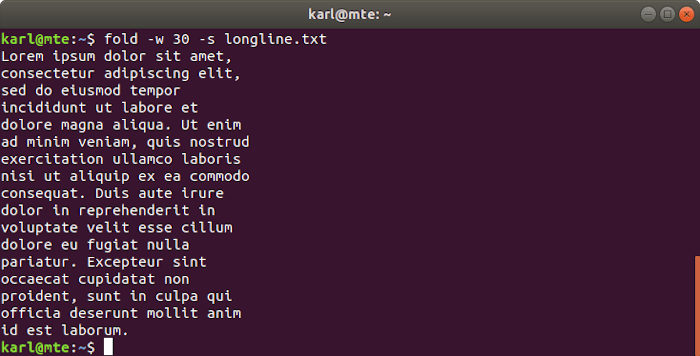
8. iconov
Esta herramienta convierte texto de una codificación a otra, lo cual es muy útil cuando se trata de codificaciones inusuales.
iconv -f input_encoding -t output_encoding -o output_file input_file
- «input_encoding» es la codificación desde la que está convirtiendo.
- «output_encoding» es la codificación a la que está convirtiendo.
- “output_file” es el nombre de archivo en el que se guardará iconv.
- «archivo_de_entrada» es el nombre de archivo del que leerá iconv.
Nota: puede enumerar las codificaciones disponibles con iconv -l
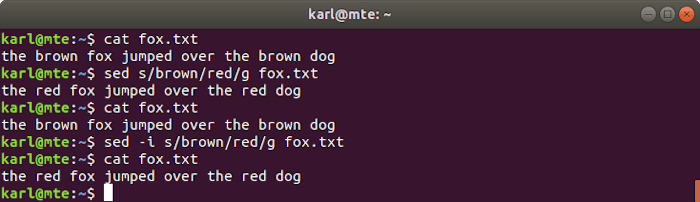
9. sed
sed es un potente y flexible stren educaritor, más comúnmente utilizado para buscar y reemplazar cadenas con la siguiente sintaxis.
El siguiente comando leerá del archivo especificado (o entrada estándar), reemplazando las partes del texto que coinciden con el patrón de expresión regular con la cadena de reemplazo y enviando el resultado a la terminal.
sed s/pattern/replacement/g filename
Para modificar el archivo original en su lugar, puede utilizar el -i bandera.
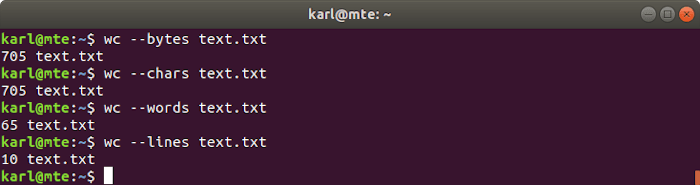
10. wc
los wc La utilidad imprime el número de bytes, caracteres, palabras o líneas en un archivo.
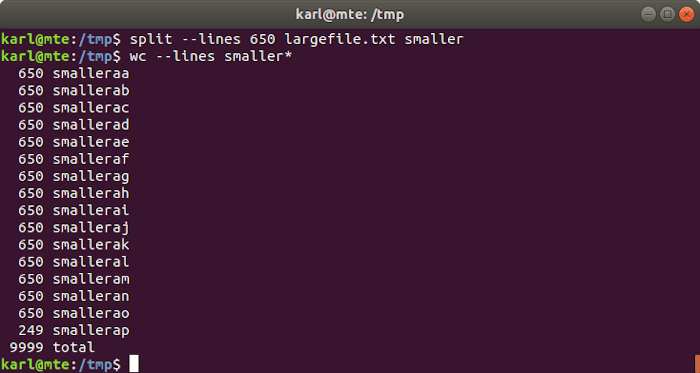
11. dividir
Puedes usar split para dividir un archivo en archivos más pequeños, por número de líneas, por tamaño o en un número específico de archivos.
Dividir por número de líneas
split -l num_lines input_file output_prefix
División por bytes
split -b bytes input_file output_prefix
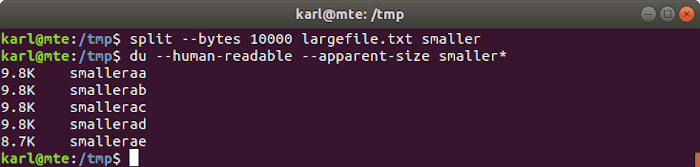
Dividir a un número específico de archivos
split -n num_files input_file output_prefix

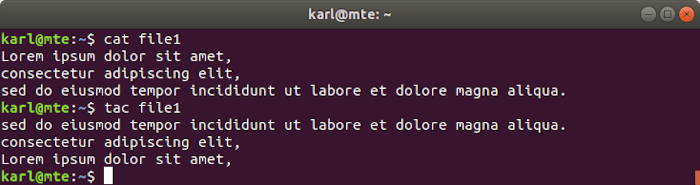
12. tac
Tac, que es gato al revés, hace exactamente eso: muestra los archivos con las líneas en orden inverso.
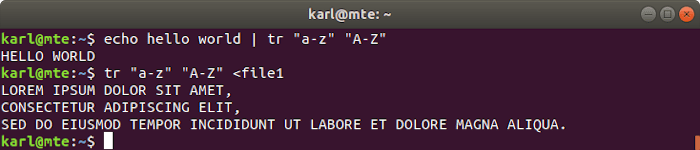
13. tr
La herramienta tr se utiliza para traducir o eliminar conjuntos de caracteres.
Un conjunto de caracteres suele ser una cadena o un rango de caracteres. Por ejemplo:
- “AZ”: todas las letras mayúsculas
- “a-z0-9”: letras minúsculas y dígitos
- «\norte[:punct:]”: caracteres de nueva línea y puntuación
Referirse a página del manual tr para más detalles.
Para traducir un conjunto a otro, use la siguiente sintaxis:
Por ejemplo, para reemplazar caracteres en minúsculas con su equivalente en mayúsculas, puede usar lo siguiente:
Para eliminar un conjunto de caracteres, utilice el -d bandera.

Para eliminar el complemento de un conjunto de caracteres (es decir, todo excepto el conjunto), utilice -dc.

Conclusión
Hay mucho que aprender cuando se trata de la línea de comandos de Linux. Con suerte, los comandos anteriores pueden ayudarlo a manejar mejor el texto en la línea de comando.