
 Fatmawati Achmad Zaenuri / Shutterstock
Fatmawati Achmad Zaenuri / Shutterstock
Bajo Linux, awk es un dínamo de manipulación de texto de línea de comandos, así como un poderoso lenguaje de secuencias de comandos. Aquí hay una introducción a algunas de sus características más interesantes.
Como awk obtuvo su nombre
los awk El comando fue nombrado usando las iniciales de las tres personas que escribieron la versión original en 1977: Alfred Aho, Peter Weinberger, y Brian Kernighan. Estos tres hombres pertenecían al legendario AT&T Laboratorios Bell Salón de la fama de Unix. Con contribuciones de muchos otros desde entonces, awk continuó evolucionando.
Es un lenguaje de secuencias de comandos completo, así como un conjunto de herramientas de manipulación de texto completo para la línea de comandos. Si este artículo le abre el apetito, puede revisa cada detalle A proposito awk y su funcionalidad.
Reglas, modelos y acciones
awk trabaja en programas que contienen reglas compuestas por modelos y acciones. La acción se realiza sobre el texto que coincide con el patrón. Los patrones están rodeados de tirantes ({}). Juntos, un modelo y una acción forman una regla. Todos awk El programa está rodeado de comillas simples (').
Echemos un vistazo al tipo más simple de awk programa. No tiene patrón, por lo que coincide con cada línea de texto que se inserta en él. Esto significa que la acción se ejecuta en cada fila. Bien úselo en la salida de los who pedido.
Aquí está la salida estándar de who:
who
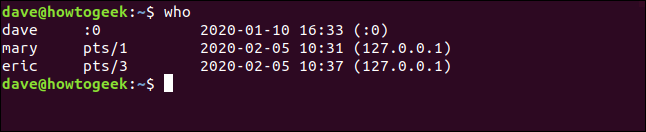
Tal vez no necesitemos toda esta información, sino que solo deseemos ver los nombres en las cuentas. Podemos dirigir la salida de who dentro awk, luego dice awk para imprimir solo el primer campo.
Por defecto, awk considera que un campo es una cadena de caracteres rodeada de espacios, el comienzo de una línea o el final de una línea. Los campos se identifican con un signo de dólar ($) y un número. Entonces, $1 representa el primer campo, que usaremos con el print acción para imprimir el primer campo.
Escribimos lo siguiente:
who | awk '{print $1}'
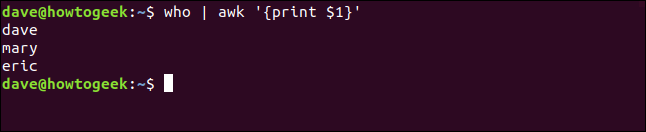
awk imprime el primer campo y borra el resto de la línea.
Podemos imprimir tantos campos como queramos. Si agregamos una coma como separador, awk imprime un espacio entre cada campo.
Escribimos lo siguiente para imprimir también la hora en que la persona inició sesión (campo cuatro):
who | awk '{print $1,$4}'
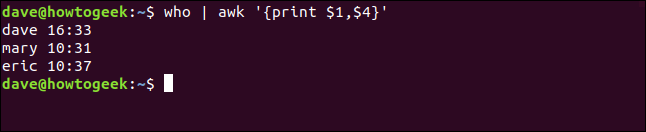
Hay algunos identificadores de campo especiales. Estos representan la línea de texto completa y el último campo en la línea de texto:
- $ 0: Representa la línea completa de texto.
- $ 1: Representa el primer campo.
- $ 2: Representa el segundo campo.
- $ 7: Representa el séptimo campo.
- $ 45: Representa el campo 45.
- $ NF: representa el «número de campos» y representa el último campo.
Escribiremos lo siguiente para que aparezca un pequeño archivo de texto que contiene una breve cita atribuida a Dennis ritchie:
cat dennis_ritchie.txt

Queremos awk para imprimir el primer, segundo y último campo de la cotización. Tenga en cuenta que, aunque está envuelto en la ventana de la terminal, es solo una línea de texto.
Escribimos el siguiente comando:
awk '{print $1,$2,$NF}' dennis_ritchie.txt

No conocemos esta «sencillez». es el campo número 18 en la línea de texto, y no nos importa. Lo que sí sabemos es que este es el último campo y podemos usar $NF para obtener su valor. El período simplemente se considera como otro carácter en el cuerpo del campo.
Agregar separadores de campo de salida
También puede decir awk para imprimir un carácter particular entre campos en lugar del carácter de espacio predeterminado. La salida predeterminada de date el comando es un poco especial porque el tiempo está inmerso en él. Sin embargo, podemos escribir lo siguiente y usar awk para extraer los campos que desee:
date
date | awk '{print $2,$3,$6}'
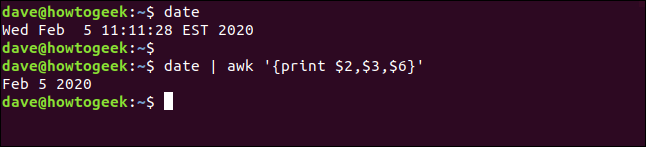
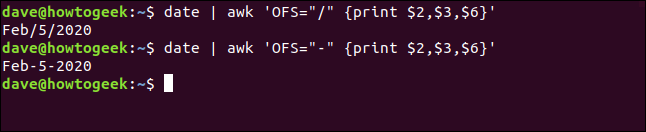
Usaremos el OFS (separador de campo de salida) variable para poner un separador entre mes, día y año. Tenga en cuenta que a continuación incluimos el comando entre comillas simples ('), no los frenillos ({}):
date | awk 'OFS="https://www.howtogeek.com/" {print$2,$3,$6}'
date | awk 'OFS="-" {print$2,$3,$6}'
Las reglas BEGIN y END
A BEGIN La regla se ejecuta una vez antes de que comience el procesamiento de texto. De hecho, se ejecuta antes awk incluso lee cualquier texto. a END la regla se ejecuta una vez que se completa todo el procesamiento. Puedes tener varios BEGIN y END reglas, y se ejecutarán en orden.
Para nuestro ejemplo de BEGIN regla, imprimiremos la cotización completa de dennis_ritchie.txt archivo que usamos anteriormente con un título arriba.
Para eso, escribimos este comando:
awk 'BEGIN {print "Dennis Ritchie"} {print $0}' dennis_ritchie.txt
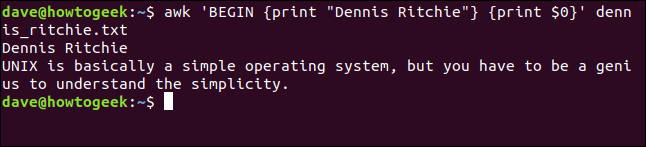
Nota la BEGIN La regla tiene su propio conjunto de acciones encerradas en su propio conjunto de llaves ({}).
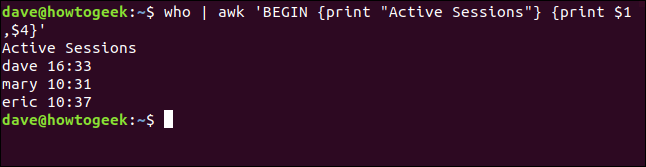
Podemos usar esta misma técnica con el comando que usamos anteriormente para dirigir la salida de who dentro awk. Para hacer esto, escribimos lo siguiente:
who | awk 'BEGIN {print "Active Sessions"} {print $1,$4}'
Separadores de campo de entrada
Si quieres awk para trabajar con texto que no usa espacios para separar campos, debe indicarle qué carácter usa el texto como separador de campo. Por ejemplo, el /etc/passwd el archivo usa dos puntos (:) para separar los campos.
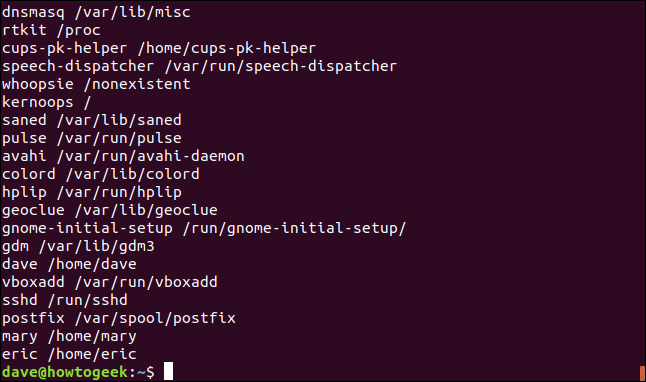
Usaremos este archivo y el -F (cadena de separación) opción para decir awk usa los dos puntos:) como separador. Escribimos lo siguiente para decir awk para imprimir el nombre de la cuenta de usuario y la carpeta de inicio:
awk -F: '{print $1,$6}' /etc/passwd

La salida contiene el nombre de la cuenta de usuario (o el nombre de la aplicación o demonio) y la carpeta de inicio (o la ubicación de la aplicación).
Agregar patrones
Si lo único que nos interesa son las cuentas de usuario normales, podemos incluir una plantilla con nuestra acción de impresión para filtrar todas las demás entradas. Porque ID de usuario los números son iguales o superiores a 1000, podemos basar nuestro filtro en esta información.
Escribimos lo siguiente para ejecutar nuestra acción de impresión solo cuando el tercer campo ($3) contiene un valor de 1000 o más:
awk -F: '$3 >= 1000 {print $1,$6}' /etc/passwd
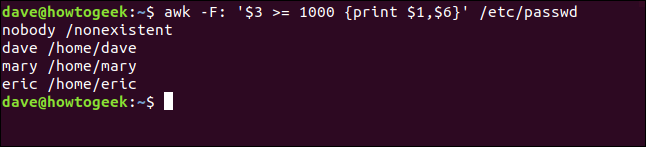
El motivo debe preceder inmediatamente a la acción a la que está asociado.
Podemos usar el BEGIN regla para dar un título a nuestro pequeño informe. Escribimos lo siguiente, usando el (n) notación para insertar un carácter de nueva línea en la cadena del título:
awk -F: 'BEGIN {print "User Accountsn-------------"} $3 >= 1000 {print $1,$6}' /etc/passwd
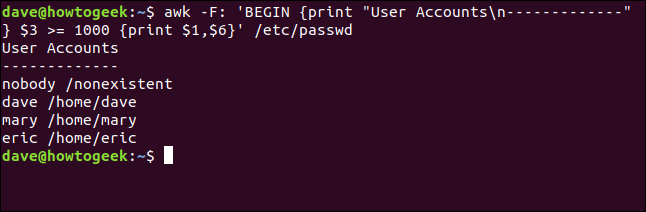
Los modelos son por derecho propio expresiones regulares, y son una de las glorias de awk.
Digamos que queremos ver identificadores únicos universales (UUID) de sistemas de archivos montados. Si miramos en el /etc/fstab archivo para apariciones de la cadena «UUID», debe devolvernos esa información.
Usamos el patrón de búsqueda «/ UUID /» en nuestro comando:
awk '/UUID/ {print $0}' /etc/fstab
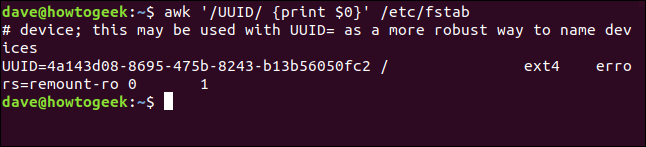
Encuentra todas las apariciones de «UUID» e imprime esas líneas. De hecho, hubiéramos logrado el mismo resultado sin el print acción porque la acción predeterminada imprime toda la línea de texto. Sin embargo, para mayor claridad, a menudo es útil ser explícito. Cuando navegue por un script o su archivo de historial, se alegrará de haber dejado pistas para usted.
La primera línea que se encontró fue una línea de comentario y, aunque la cadena «UUID» estaba en el medio, awk lo encontré de nuevo. Podemos modificar la expresión regular y decir awk para procesar solo las líneas que comienzan con «UUID». Para hacer esto, escribimos lo siguiente que incluye el token de inicio de línea (^):
awk '/^UUID/ {print $0}' /etc/fstab

¡Es mejor! Ahora solo vemos instrucciones de montaje genuinas. Para refinar aún más la salida, escribimos lo siguiente y limitamos la visualización al primer campo:
awk '/^UUID/ {print $1}' /etc/fstab

Si tuviéramos varios sistemas de archivos montados en esta máquina, obtendríamos una tabla ordenada de sus UUID.
Funciones integradas
awk Para muchas funciones que puede llamar y utilizar en sus propios programas, tanto desde la línea de comandos como en scripts. Si excava, lo encontrará muy exitoso.
Para demostrar la técnica general de llamar a una función, veremos algunas numéricas. Por ejemplo, lo siguiente imprime la raíz cuadrada de 625:
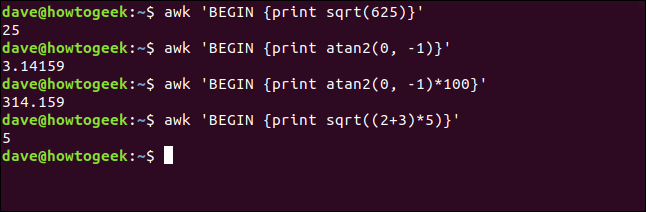
awk 'BEGIN { print sqrt(625)}'
Este comando imprime el arcotangente de 0 (cero) y -1 (que resulta ser la constante matemática, pi):
awk 'BEGIN {print atan2(0, -1)}'
En el siguiente comando, modificamos el resultado de la atan2() función antes de imprimirlo:
awk 'BEGIN {print atan2(0, -1)*100}'
Las funciones pueden aceptar expresiones como parámetros. Por ejemplo, aquí hay una forma complicada de pedir la raíz cuadrada de 25:
awk 'BEGIN { print sqrt((2+3)*5)}'
guiones awk
Si su línea de comando se complica, o si está desarrollando una rutina que sabe que desea reutilizar, puede transferir su awk comando en un script.
En nuestro script de muestra, haremos todo lo siguiente:
- Dígale al shell qué ejecutable usar para ejecutar el script.
- Preparar
awkusar elFSvariable de separación de campo para leer el texto de entrada con campos separados por dos puntos (:). - Utilizar el
OFSseparador de campo de salida para decirawkusa los dos puntos:) para separar los campos en la salida. - Establezca un contador en 0 (cero).
- Establezca el segundo campo en cada línea de texto en un valor vacío (siempre es una «x», por lo que no es necesario que lo veamos).
- Imprime la línea con el segundo campo modificado.
- Incrementa el contador.
- Imprime el valor del contador.
Nuestro guión se muestra a continuación.
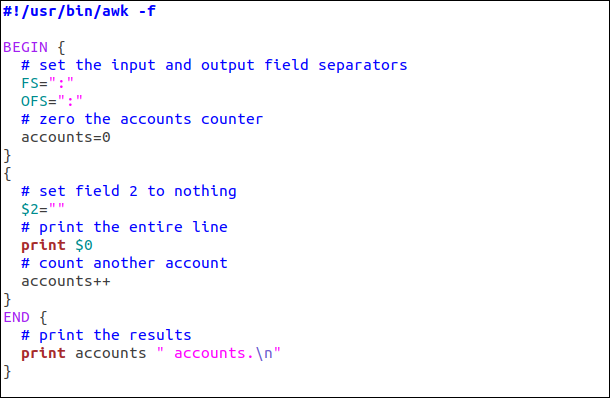
los BEGIN regla realiza los pasos preparatorios, mientras que el END La regla muestra el valor del contador. La regla del medio (que no tiene nombre, ni patrón por lo que corresponde a cada línea) modifica el segundo campo, imprime la línea e incrementa el contador.
La primera línea del script le dice al shell qué ejecutable usar (awk, en nuestro ejemplo) para ejecutar el script. También pasa el -f opción (nombre de archivo) para awk, que le informa que el texto que va a procesar vendrá de un archivo. Pasaremos el nombre del archivo al script cuando lo ejecutemos.
Hemos incluido el siguiente script como texto para que pueda cortar y pegar:
#!/usr/bin/awk -f
BEGIN {
# set the input and output field separators
FS=":"
OFS=":"
# zero the accounts counter
accounts=0
}
{
# set field 2 to nothing
$2=""
# print the entire line
print $0
# count another account
accounts++
}
END {
# print the results
print accounts " accounts.n"
}
Guárdelo en un archivo llamado omit.awk. PARA hacer que el script sea ejecutablemi, escribimos lo siguiente usando chmod:
chmod +x omit.awk

Ahora vamos a ejecutarlo y gastar el /etc/passwd archivo a secuencia de comandos. Este es el archivo awk procesará por nosotros, usando las reglas del script:
./omit.awk /etc/passwd

El archivo se procesa y se muestra cada línea, como se muestra a continuación.
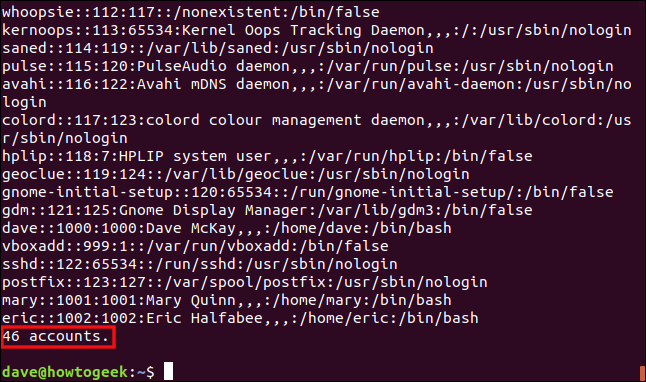
Las entradas «x» en el segundo campo se han eliminado, pero tenga en cuenta que los separadores de campo todavía están presentes. Las líneas se cuentan y el total se muestra en la parte inferior de la salida.
awk no significa incómodo
awk no significa molesto; representa elegancia. Ha sido descrito como un filtro de procesamiento y redactor de informes. Específicamente, es ambos, o más bien una herramienta que puede usar para ambas tareas. En unas pocas líneas awk hace lo que requiere una codificación extensa en un lenguaje tradicional.
Este poder es aprovechado por el concepto simple de reglas que contienen modelos, que seleccionan el texto a procesar y las acciones que definen el procesamiento.